
“Oracle Database In-Memory” es una nueva y poderosa funcionalidad del manejador de base de datos que fue incluida en la versión 12 Realease 1 (12.1.0.2), liberada en julio del 2014.Esta serie de artículos estarán basados sobre esta interesante posibilidad que nos pone a disposición “Oracle Database”.
Introducción
El tema relacionado con “Oracle Database 12c In-Memory” definitivamente ha de marcar un antes y un después en la forma en como los sistemas y/o bases de datos de tipo “OLTP” & “DWH” pueden combinarse basados en una base de datos Oracle. Hasta la fecha los sistemas de procesamiento común cuenta con una o muchas base(s) de datos con procesamiento de tipo “OLTP” y una o muchas base(s) de datos de tipo “DWH” para llevar a cabo análisis de inteligencia de negocio. Normalmente esto conduce a que los clientes adquieran en la mayoría de los casos distintas infraestructuras de “Hardware” ( Base de datos.. Servidores.. etc.. ) para mantener la operación de ambos. De forma común los clientes diseñan, implantan soluciones y procesos para alimentar las bases de datos de tipo “DWH” con la data generada por los sistemas “OLTP”. Desde hace unas cuantas décadas siempre se ha realizado de la misma manera en la mayoría de oportunidades.
Ahora que tal si hablamos de:Combinar ambos productos y/o funcionalidades en una misma base de datos.. eliminando de forma parcial o total procesos de: extracción, transporte, transformación y análisis..
- Poseer un DWH que pueda correr en tiempo real..
- Menor integración, esfuerzo de administración..
- Nuevos posibles tipos de aplicaciones de apoyo de decisiones en tiempo real..
- Esto y mucho mas..
“Oracle Database In-Memory” acelera transparente el análisis en órdenes de magnitud, mientras que al mismo tiempo puede acelerar cargas de trabajo mixtas en una base de datos de tipo OLTP. Con “Oracle Database In-Memory”, los usuarios obtienen respuestas inmediatas a preguntas de negocio que previamente tomaban horas.
“Oracle Database In-Memory” ofrece tecnología de vanguardia en materia de rendimiento en memoria sin la necesidad de restringir funcionalidad o aceptar cierta clase de compromisos transaccionales, configuración, complejidad o riesgo. La Implementación de “Oracle Database In-Memory” con cualquier aplicación compatible con bases de datos Oracle es tan fácil como apretar un botón, no se requieren cambios en las aplicaciones. “Oracle Database In-Memory” está totalmente integrado con los conceptos ampliamente conocidos y manejados por el manejador Oracle en su arquitectura tales como:
- “Scale-up”
- “Scale-out”
- Almacenamiento por niveles
- Disponibilidad
- & Tecnologías de seguridad
“Oracle Database In-Memory” ofrece la capacidad de realizar fácilmente análisis de data en modo “real-time” en conjunto con procesamiento de transacciones también en tiempo real. Esto representa un concepto de transformación de procesamiento empresarial escalando a un concepto de “Real-Time Enterprises” las cuales podrán procesar decisiones, responder instantáneamente a solicitudes de los clientes y mas en tiempo real..
Todo esto y mas es lo que representa una de las mas novedosas caracterististicas de “Oracle Database 12c” denominada: “Oracle Database12c In-Memory”.
Todo esto y mas es lo que representa una de las mas novedosas caracterististicas de “Oracle Database 12c” denominada: “Oracle Database12c In-Memory”.
Hablemos técnicamente un poco mas de esta nueva característica.
Bloque de base de datos
El manejador de base de datos Oracle tradicionalmente ha almacenado los datos en formato de fila (“row format”), esto significa: guardados como registros “multi-columna” en los bloques de datos en disco (Figura 1). En una base de datos “row format”, cada nueva transacción o registro es guardado como una nueva fila en una tabla. El formato de fila, es ideal para bases de datos transaccionales (OLTP) ya que permite un rápido acceso a todas las columnas de un registro, dado que todos los datos de un registro específico se mantienen contiguos tanto en la memoria como en el disco, también es marcadamente eficiente para el procesamiento de sentencias DML.
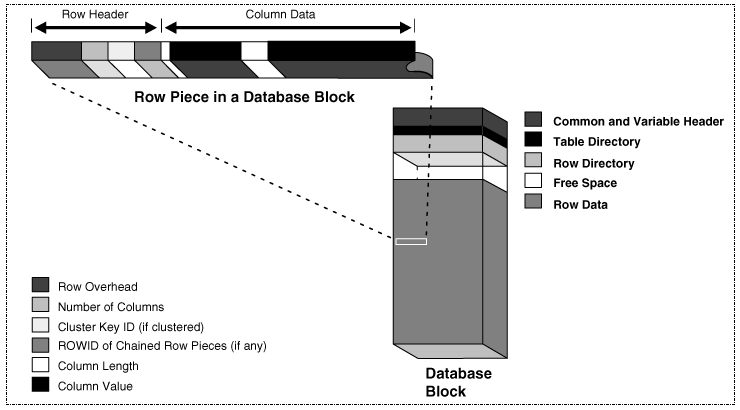
Figura 1: Formato interno de un bloque de base de datos y una pieza de fila
Aclaramos que la estructura del bloque de datos no fue modificada en el último release de “Oracle Database”, los cambios se realizaron únicamente en la arquitectura de la memoria lo cual implica solamente impacto a nivel instancia.
El manejador de base de datos Oracle tradicionalmente ha almacenado los datos en formato de fila (“row format”), esto significa: guardados como registros “multi-columna” en los bloques de datos en disco (Figura 1). En una base de datos “row format”, cada nueva transacción o registro es guardado como una nueva fila en una tabla. El formato de fila, es ideal para bases de datos transaccionales (OLTP) ya que permite un rápido acceso a todas las columnas de un registro, dado que todos los datos de un registro específico se mantienen contiguos tanto en la memoria como en el disco, también es marcadamente eficiente para el procesamiento de sentencias DML.
Figura 1: Formato interno de un bloque de base de datos y una pieza de fila
Aclaramos que la estructura del bloque de datos no fue modificada en el último release de “Oracle Database”, los cambios se realizaron únicamente en la arquitectura de la memoria lo cual implica solamente impacto a nivel instancia.
Cambios en la Instancia
Una instancia Oracle está compuesta por memoria y procesos de segundo plano “Background processes”. La memoria está dividida principalmente en dos áreas diferentes: “System Global Area (SGA)” and “Program Global Area”. Oracle crea procesos servidor para manejar los requerimientos de los procesos de usuarios conectados a la instancia. Una de las tareas más importantes de estos procesos de servidor (“Server Process”) es leer bloques de datos de los objetos desde los datafiles en disco y cargarlos en el buffer chache. Por defecto Oracle almacena los datos en el “database buffer cache” en formato fila (“row format”). A partir de Oracle Database 12c Release 1 (12.1.0.2) se agregó un nuevo pool estático en la SGA llamado área de “In-Memory” de esta manera los objetos son almacenados en un nuevo formato denominado “In-Memory Column Store (IM column store)” en esta mencionada área de memoria. IM Column es un opcional que almacena copias de tablas, particiones, columnas de tablas, vistas materializadas (objetos especificados como “In-memory” utilizando DDL) en un nuevo formato columnar optimizado para escaneos rápidos.
La base de datos utiliza técnicas especiales, incluyendo procesamiento de instrucciones de vector SIMD (utilizado para procesar varios valores en cada instrucción) para escanear datos columnares rápidamente. “IM column store” es un complemento para el “data buffer cache” más que un reemplazo del mismo. De hecho ambas áreas de memoria pueden almacenar los mismos datos en diferentes formatos (Figura 2) y no es requerido que los objetos que son cargados en el “IM column store” sean también cargados en el “database buffer cache”, es decir, los objetos pueden ser subidos a memoria únicamente en “IM column store”.
No hay comentarios:
Publicar un comentario